전 과정에서 공공 데이터 포털의 메타데이터들을 파싱한 후 그 데이터들을 json파일로 저장하는 과정과 그 메타데이터들의 필요한 요소들만을 dcat어휘와 매핑하는 과정을 끝마쳤다. 이제 그 다음 할 일은 이 json 파일을 rdf 파일 형식으로 변환하는 것이다.
4. RDF 파일 생성
4.1 적절한 자료구조 선택
rdf 파일은 s, p, o 형태로 쓰여져 있다. 여기서 s는 subject, p는 predicate, o는 object의 약자이다. 즉, 이 메타데이터들은 s인 데이터셋 이름과 p인 메타데이터 종류, 그리고 o인 메타데이터 내용으로 표현될 수 있다는 것이다. 이는 tree 자료구조로 표현되는것이 적합하다고 생각했다. rdf파일은 tree 구조로 저장된 내용을 level-order로 rdf 형식에 맞게 출력하면 그만이었다. 그러므로 이 json 파일 안의 내용을 매핑한 어휘를 사용해 tree 구조로 저장해 보았다.
4.2 RDF 파일 생성
우선 진행할 과정은 다음과 같다:
- json 파일 불러오기
- 빈 RootTree 생성하기
- 메타데이터 구조에 맞게 RootTree에 SubTree 채워 넣기
- rdf 형식에 맞게 RootTree를 level-order 순으로 출력해 저장하기
전체 코드는 하나의 파일에 작성하였지만 진행 과정에 맞게 나눠서 설명한다.
4.2.1 json 파일 불러오기
불러올 파일들은 총 두개, result.json과 mapping.json이다.
result.json은 메타데이터들의 json 파일이고, mapping.json은 매핑된 어휘의 json파일이다. mapping.json의 내용은 다음과 같다.
{
"publicDataSj": "dct:title",
"publicDataEngSj": "dct:title@en",
"publicDataSjEn": "dct:title@en",
"publicDataDc": "dct:description",
"publicDataDcEn": "dct:description@en",
"kwrd": "dcat:keyword",
"kwrdEn": "dcat:keyword@en",
"registDt": "dct:issued",
"updtDt": "dct:modified",
"registerId": "dct:creator",
"jrsdMiryfcCode": "dct:spatial",
"DataNm": "dct:title",
"DataNmEn": "dct:title@en",
"DataDc": "dct:description",
"DataDcEn": "dct:description@en",
"atchFileExtsn": "dct:format",
"downloadUrl": "dcat:downloadURL"
}
그리고 json 파일을 불러오는 코드는 다음과 같다. json 파일을 파이썬에서 불러오면 dictionary 형태로 불러와진다.
with open('../result.json', encoding="utf-8-sig") as json_file:
json_datum = json.load(json_file)
with open('mapping.json', encoding='utf-8-sig') as json_file:
json_map = json.load(json_file)
4.2.2 빈 RootTree 생성하기
파이썬에서 tree를 다루는 방법은 여러 가지가 있는데 여기서는 anytree라는 라이브러리를 사용했다. anytree의 사용법은 다음과 같다. LINK
우선 빈 RootTree를 생성하기 전에 각각의 데이터셋 당 하나의 RootTree를 생성해 리스트에 저장하기로 했다. 이렇게 하는 편이 tree를 다루기에 쉬울 것 같기 때문이다.
all_node_set = []
print('Start making tree')
for index, i in enumerate(json_datum):
dataset = json_datum[i]
root = Node(':dataset-' + i, data='')
temp_node = Node('rdf:type', parent=root, data='dcat:Dataset')
json_datum[i]을 dataset이라는 변수로 선언하였는데, 여기서 dataset은 json_datum이라는 dictionary에서 i라는 key값을 넣어 얻은 value이므로 이것이 바로 메타데이터라고 볼수 있다. 이는 뒤에서 메타데이터들을 조작할 때 사용된다.
하나의 dcat:Dataset 안에 여러 개의 dcat:Distribution이 있는 구조이므로 rootTree의 이름을 :dataset-number로 그 안의 첫번째 요소를 name은 rdf:type, data는 dcat:Dataset으로 subtree를 만들어주었다. 즉 다음과 같은 rdf 형식을 나타내는 것이다.
:dataset-number rdf:type dcat:Dataset .
이런 식으로 모든 메타데이터들에 대해 이러한 빈 RootTree를 만들어 all_node_set 리스트에 저장한다.
4.2.3 메타데이터 구조에 맞게 RootTree에 SubTree 채워 넣기
자, 이제 해야할 일은 우리가 만들 rdf 파일을 tree 구조로 생성하는 것이다. 위에서 각각의 메타데이터에 적합한 dcat 표준 어휘를 매핑한 json 파일을 사용하고 만약 그에 맞지 않는 구조로 이루어져 있는 경우, 무시하고 진행하거나 직접 tree를 생성해주는 과정을 통해 SubTree를 생성한다.
우선 첫 번째로 데이터셋의 URL과 publicDataPk라는 keyword를 가진 정보를 비교해보니 publicDataPk는 URL에 포함되어 있는 데이터셋의 고유한 코드라는것을 알아내었다.
url_code = dataset['publicDataPk']
url = 'https://www.data.go.kr/dataset/' + url_code + '/fileData.do'
temp_node = Node('dcat:landingPage', parent=root, data='<' + url + '>')
dcat:landingPage는 데이터셋을 설명해주거나 보여주는 웹 사이트 또는 홈페이지를 뜻하는 dcat 어휘이므로 위의 코드는 결국 :dataset-number dcat:landingPage <URL> .을 나타낸다고 볼 수 있다. 이와 같이 다른 메타데이터들을 대상으로 rdf 파일을 작성한다.
for tag in dataset:
우선 위에서 선언한 dataset이라는 메타데이터에서 for loop로 tag라는 메타데이터의 유형을 나타내는 단어를 뽑아낸다.
if tag in json_map and dataset[tag] != '':
spec = dataset[tag]
if json_map[tag] == 'dcat:keyword@en' or json_map[tag] == 'dcat:keyword':
spec = myutil.get_keyword(spec, json_map[tag])
temp_node = Node(json_map[tag][0:len(json_map[tag]) - 3], parent=root,
data=spec.replace("<br>", "").replace("<BR>", ""))
elif '@en' in json_map[tag]:
temp_node = Node(json_map[tag][0:len(json_map[tag]) - 3], parent=root,
data='"' + spec.replace('"', "'").replace("<br>", "").replace("<BR>", "") + '"@en')
else:
temp_node = Node(json_map[tag], parent=root,
data='"' + spec.replace('"', "'").replace("<br>", "").replace("<BR>", "") + '"')
all_node_set.append(root)
우선 위의 코드는 tag가 json_map에 포함되어 있고 비어있는 값이 아닌 경우 실행되는 코드이고, 이는 전에 말한 details 안에 포함된 각각의 데이터를 설명해주는 것이 아닌 전체 데이터셋의 공통된 정보를 설명해주는 메타데이터를 처리하는 코드이다.
여기서 복잡한 예외 처리들이 눈에 보인다. 우선 첫 번째로 볼수 있는 것은 keyword를 처리해주는 구문이다. 우리가 수집한 원본 메타데이터에서는 keyword를 나타낼 때, 하나의 문자열로 구성되고 “k1@k2@k3”와 같이 각각의 단어들을 ‘@’로 구분지어 놓음으로서 나타낸다. 그러므로 get_keyword라는 함수를 만들어 rdf 형식에 맞게 조작해주었다.
def get_keyword(keyword, lang):
keylist = keyword.split('@')
all_keys = ''
for i, key in enumerate(keylist):
key = key.strip()
key = '"' + key + '"'
if lang == 'dcat:keyword@en':
key += '@en'
all_keys += key
if i != len(keylist) - 1:
all_keys += ', '
return all_keys
또한 영어 문자열에 대한 처리도 필요했다. @en과 같이 문자열 뒤에 language code가 붙여져 있는 꼴로 표현하는데 이를 mapping table에서 본 것과 같이 영어 문자열을 나타내는 메타데이터들 뒤에 @en이라는 식별자를 붙이고, 이것들이 붙여져 있는 것들만을 처리해 주는 것을 elif '@en' in json_map[tag]: 구문을 통해 확인할 수 있다.
마지막으로 else: 구문은 어떠한 예외 처리도 필요로 하지 않는 경우 실행되는 코드이다. 하지만, temp_node를 선언하는 것에서 3가지의 경우 모두가 가지고 있는 공통점이 있는데 바로 data를 처리해주는 부분이다. 저 부분은 큰따옴표(“)로만 선언이 되어 있는 메타데이터의 문자열 안에 큰따옴표가 있을 경우 rdf 파일 형식에 맞기 않기 때문에 작은따옴표(‘)로 변환해주는 처리와, 문자열 안에 줄바꿈 즉, <br>이 있을 경우 또한 처리해주었다.
이러한 방식으로 details 안의 것들도 tree로 생성해 주었다.
if tag == 'details':
details = dataset[tag]
for idx, detail in enumerate(details):
subRoot = Node(':dataset-' + i + '-' + str(idx + 1), data='')
temp_node = Node("dcat:Distribution", parent=root, data=':dataset-' + i + '-' + str(idx + 1))
temp_node = Node('rdf:type', parent=subRoot, data='dcat:Distribution')
temp_node = Node('dcat:accessURL', parent=subRoot, data='<' + url + '>')
provedData = detail['provedData']
for element in detail:
if element in json_map and detail[element] != '':
if '@en' in json_map[element]:
temp_node = Node(json_map[element][0:len(json_map[element])-3], parent=subRoot,
data='"' + detail[element]
.replace('"', "'").replace("<br>", "").replace("<BR>", "") + '"@en')
else:
temp_node = Node(json_map[element], parent=subRoot,
data='"' + detail[element]
.replace('"', "'").replace("<br>", "").replace("<BR>", "") + '"')
for element in provedData:
if element in json_map and provedData[element] != '':
if '@en' in json_map[element]:
temp_node = Node(json_map[element][0:len(json_map[element])-3], parent=subRoot,
data='"' + provedData[element]
.replace('"', "'").replace("<br>", "").replace("<BR>", "") + '"@en')
else:
temp_node = Node(json_map[element], parent=subRoot,
data='"' + provedData[element]
.replace('"', "'").replace("<br>", "").replace("<BR>", "") + '"')
all_node_set.append(subRoot)
데이터셋 안의 개별 데이터들의 메타데이터를 rdf로 변환하는 코드이다. dataset-number-number의 형식으로 지정된 이름을 가지고, dcat:Distribution이라는 표준 어휘로 표현될 수 있다. tree 구조로 표현하자면, tree의 이름이 다르기 때문에 all_node_set에 RootTree와 함께 넣어주고 나중에 출력 시 정렬하는 식으로 진행했다.
하지만 여기서 또 하나의 예외를 처리해주었다. 바로 jrsdMiryfcCode인데 이는 행정 구역이나, 정부 기관같은 데이터들을 만들어내는 기관을 알려주는 코드인데, 이것 또한 다르게 처리해주었다.
def get_instt(node, dataset):
spec = dataset['details'][0]['insttCodeInfo']['trgetInsttNm']
temp_node = Node('dct:spatial', parent=node,
data='"' + spec.replace('"', "'").replace("<br>", "").replace("<BR>", "") + '"')
try:
spec = dataset['details'][0]['insttCodeInfo']['trgetInsttNmEn']
temp_node = Node('dct:spatial', parent=node,
data='"' + spec.replace('"', "'").replace("<br>", "").replace("<BR>", "") + '"@en')
except:
None
이제 트리를 만드는 과정은 끝이 났다. 마지막으로 all_node_set 리스트를 이름 순으로 정렬 후 출력만 하면 rdf 파일 생성은 끝이 난다.
all_node_set = sorted(all_node_set, key=lambda node: int(node.name.split('-')[1]) * 10 +
(0 if len(node.name.split('-')) == 2
else int(node.name.split('-')[2])))
특별한 instance인 tree를 정렬해야 하므로, sorted 함수를 이용해 all_node_set의 각각의 node에서 데이터셋 번호를 오름차순으로 정렬해 주는 과정을 진행했다. 이제 출력할 일만 남아있다.
4.2.4 rdf 형식에 맞게 RootTree를 level-order 순으로 출력해 저장하기
rdf 형식은 rdf-turtle로 결정했으며, 출력하기 전 print 함수를 통해 내용을 본 결과다.
print('\n=====RESULT=====\n')
for i in all_node_set:
for node in LevelOrderIter(i):
check_indent = 0
if hasattr(node, 'data'):
check_end = '' if node.data == '' else ';'
print('{}{} {} {}'.format(node.depth * t, node.name, node.data, check_end))
print('\t.')
=====RESULT=====
:dataset-7314
rdf:type dcat:Dataset ;
dcat:landingPage <https://www.data.go.kr/dataset/15036201/fileData.do> ;
dct:title "전라남도 장애인복지시설 현황" ;
dct:description "전라남도 장애인 복지시설 시설명, 연락처 등" ;
dcat:keyw "장애우", "복지시설", "직업재활" ;
dct:creator "wnstjd0146" ;
dct:issued "2019-05-21 10:30:44" ;
dct:modified "2019-06-03 17:38:36" ;
dct:spatial "6460000" ;
dcat:Distribution :dataset-7314-1 ;
dcat:Distribution :dataset-7314-2 ;
dcat:Distribution :dataset-7314-3 ;
dcat:keyword "Welfare Facilities"@en, "Vocational Rehabilitation"@en ;
dct:title "Jeollanamdo Welfare Facilities for Persons with Disabilities"@en ;
dct:description "Jeollanam-do Welfare facility for the disabled Facility name, contact information"@en ;
dct:spatial "전라남도" ;
dct:spatial "Cholla province"@en ;
.
:dataset-7314-1
rdf:type dcat:Distribution ;
dcat:accessURL <https://www.data.go.kr/dataset/15036201/fileData.do> ;
dct:creator "wnstjd0146" ;
dct:issued "2019-05-28 14:45:37" ;
dct:modified "2019-05-28 16:59:53" ;
dct:format "CSV" ;
dct:creator "wnstjd0146" ;
dct:issued "2019-05-28 14:45:37" ;
dct:modified "2019-05-28 16:56:09" ;
.
:dataset-7314-2
rdf:type dcat:Distribution ;
dcat:accessURL <https://www.data.go.kr/dataset/15036201/fileData.do> ;
dct:creator "wnstjd0146" ;
dct:issued "2019-05-28 14:45:37" ;
dct:modified "2019-05-28 16:59:24" ;
dct:format "CSV" ;
dct:creator "wnstjd0146" ;
dct:issued "2019-05-28 14:45:37" ;
dct:modified "2019-05-28 16:55:36" ;
.
잘 나오는 것을 확인했으니, 이제 rdf 파일로 출력하기만 하면 된다.
print('Start saving')
rdf_file = open('result.ttl', 'w', encoding='utf-8')
for idx, i in enumerate(all_node_set):
for node, has_more in myutil.lookahead(LevelOrderIter(i)):
if hasattr(node, 'data'):
check_end = '' if node.data=='' else ';'
if not has_more:
check_end = ''
rdf_file.write('{}{} {} {}\n'.format(node.depth * t, node.name, node.data, check_end))
rdf_file.write('\t.\n\n')
print('process: {}/{}'.format(idx + 1, len(all_node_set)))
다행히도 anytree 라이브러리에서 기본적으로 level-order 이터레이터를 지원하는 함수가 존재해서 level-order로 출력할 수 있었다. 또한 lookahead 함수가 눈에 뜨이는데, 이는 다음과 같다:
def lookahead(iterable):
it = iter(iterable)
last = next(it)
for val in it:
yield last, True
last = val
yield last, False
매우 간단한 함수인데, 이터레이터의 마지막의 요소를 판별해주는 함수이다. 마지막이면 True, 아니면 False를 이터레이터와 함께 반환한다.
rdf 파일 결과는 다음과 같다. 위 prefix와 base는 코드에서 작성한 것이 아닌 직접 작성한 것이다.
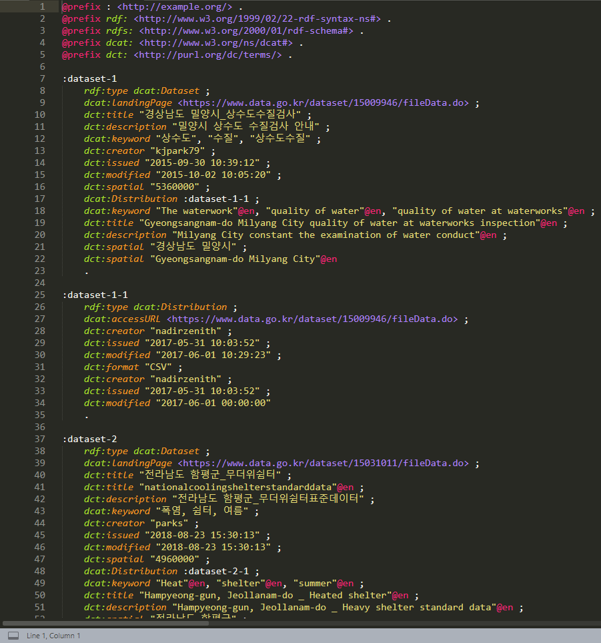
이렇게 rdf 파일 생성이 끝났다. 이제 apache jena에 이 파일을 올려 작업해야 한다.